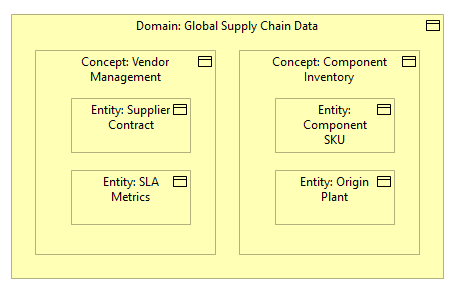
What it shows:
A high-level, business-friendly taxonomy of the data the organization cares about. It breaks down broad “Information Domains” into narrower “Concepts”, and finally down to specific “Entities”.
Why it’s needed:
Vocabulary alignment and data governance. This ensures that when the business sponsor says, “Customer Data” and the technical architects say, “Customer Data,” they mean the exact same thing. It prevents catastrophic misunderstandings during data migration or platform integration, proving to Data Governance and InfoSec teams exactly what categories of data are entering the system.
When to use it:
Highly recommended for SADs and HLDs on data-heavy deployments, massive COTS platforms acting as a System of Record, or complex data migration projects. Even though a vendor dictates the underlying database schema in a COTS product, this map is still needed to prove how the business vocabulary maps to the vendor’s tool.
When NOT to use it:
Generally best to omit for pure “plumbing” or infrastructure projects (e.g., deploying load balancers, bare-metal server provisioning, upgrading network switches). If the system just moves encrypted packets from Point A to Point B and does not care about the business context of the payload, an Information Map is completely irrelevant.
Example: